Appearance
Daemon channel
To fulfill a request from a client to a service, a snet-daemon needs to store and process information about the service payment. This connection is called the payment channel.
If there is only one service and corresponding snet-daemon the process is easy:

When payment passes a validation process, the payment channel is stored in an internal storage to be claimed when the service successfully accomplishes the request.
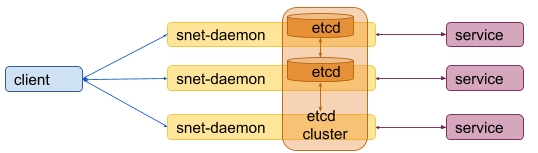
The situation becomes more complicated if a service provides several replicas. In this case it is not possible to have several separated snet-daemons each of which has an independent internal storage.
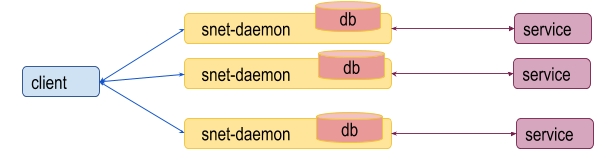
One drawback of using a separated payment channel for each replica, is that it can be expensive from the gas consumption and time execution point of view, because each operation to open a channel requires it to be processed by the Blockchain.
The other one is that such model is subject to an attack where the same payment can be used for services from different replicas. This leads to a model where all snet-daemons for the same service should use the shared storage.
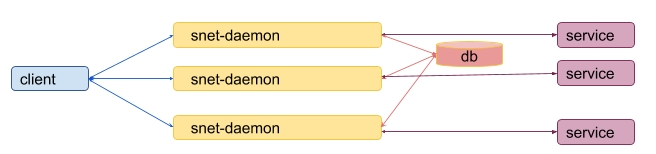
However, if only one instance of a storage is provided it can easily become a single point of failure for the whole system. When it fails, this leads to failure of all payments even when there are live replicas.
Therefore, we are using distributed storage. There is plenty of available storage, and we just need to make the optimal choice. We are adhering to several criteria:
According to CAP theorem, we only have a choice to select two out of three main guarantees:
- Partition tolerance
- Availability
- Consistency
We need a partition tolerance distributed storage to save system from network failures. Furthermore, we also need storage that provides strong consistency guarantees to avoid a situation where the same payment is used twice on different replicas.
This does not mean that the availability guarantee is not important. This means that if all but a few nodes of the distributed storage are still available, it will not be possible to read/write requests. This is a price we are paying in exchange for a strong consistency storage system.
Lets strike out the availability guarantee and leave only partition tolerance and consistency:
- Partition tolerance
Availability- Consistency
The new design now looks like this:
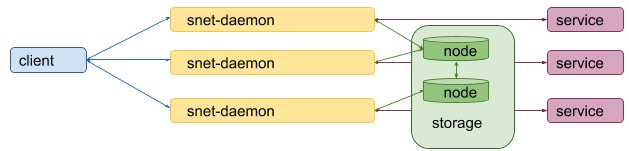
The current approach is fine, but it requires for a service owner not only to setup a snet-daemon for each replica, but also to deploy a separated distributed storage. This can be a rather tedious and complicated task.
To avoid this, it would be good to incorporate the distributed storage nodes into snet-daemons so it would be the snet-daemon's task to run required distributed storage nodes:
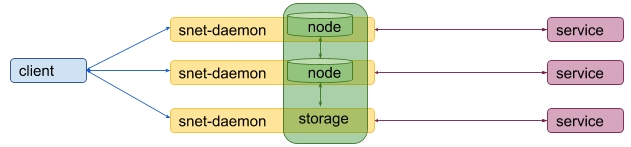
Considered storages
We are looking for a distributed storage with strong consistency guarantees which can be run by snet-daemon (e.g. be easily integrated into a Go program).
Some of the storages that were considered are:
| Distributed Storage | Language | Consensus | Embedded Server Support |
|---|---|---|---|
| Etcd | Go | Raft | native |
| Consul | Go | Raft | ticket 467 |
| ZooKeeper | Java | ZAB | native |
Etcd was chosen because it is written in Go, and has out of the box embedded server support. This means that its nodes can be started and stopped by snet-daemon replicas.
It is not clear whether it is possible to run a consul server agent from a Go application. A few examples (embedded-consul 12 just bundles the Consul as a binary package.
Zookeeper is just written in Java and it requires to have an additional support to start Zookeeper nodes from Go.
Note: all these storages use a quorum to get a consensus during leader election and values writings. This means that if the number of failed nodes are more than half of all nodes, then the the cluster stops working. As it was described before, this is a cost for a distributed system to provide strong consistency guarantees.
Etcd storage
Running and accessing embedded etcd cluster
Starting an etcd node requires at least the following parameters:
- name: human-readable name for the node.
- listen-client-urls: list of URLs to listen on for client traffic
- listen-peer-urls: list of URLs to listen on for peer traffic
- initial-cluster: initial cluster configuration for bootstrapping, for example:
name1=http://AAA.BBB.1.1:2380,name2=http://AAA.BBB.1.2:2380 - initial-cluster-token: initial cluster token for the etcd cluster during bootstrap
There are some throughput tests which run several etcd nodes locally and measure number of writes, and compare and set requests per seconds.
Note: because all etcd nodes were run locally, the results can be different from when each etcd node is ran on its own separated server.
etcd cluster size
According to the etcd FAQ it is suggested to have an odd number of etcd nodes in a cluster, usually 3 or 5. It also mentions that "Although larger clusters provide better fault tolerance, the write performance suffers because data must be replicated across more machines."
Proposed solutions
The following solutions are based on the embedded etcd storage discussed in details in chapters below:
- Command line etcd cluster creation
- Fixed size etcd cluster
- Incremental etcd cluster creation
Command line etcd cluster creation
This approach is to add a command line option to snet-cli which allows us to start an etcd instance as part of etcd cluster:
snet storage init --name name --token unique-token --client-url http://AAA.BBB.1.1:2379 --peer-url http://AAA.BBB.1.1:2380 --initial-cluster name1=http://AAA.BBB.1.1:2380,name2=http://AAA.BBB.1.2:2380
The list of client-urls then needs to be passed to each replica to have access to the etcd cluster storage.
Fixed size etcd cluster
This approach assumes that etcd nodes are started by replicas and that the size of etcd cluster is fixed. The initial configuration file contains a list of all replicas and information whether it should start etcd node or not:
For example:
| replica id | start etcd node | etcd node name | etcd node client url | etcd node peer url |
|---|---|---|---|---|
| replica 1 | yes | node1 | http://AAA.BBB.1.1:2379 | http://AAA.BBB.1.1:2380 |
| replica 2 | yes | node2 | http://AAA.BBB.1.2:2379 | http://AAA.BBB.1.2:2380 |
| replica 3 | no | |||
| replica 4 | yes | node3 | http://AAA.BBB.1.4:2379 | http://AAA.BBB.1.4:2380 |
| replica 5 | no |
Such a configuration requires that all replicas which maintain an etcd node need to be started first to have a functional etcd cluster.
Incremental etcd cluster creation approach
Starting etcd cluster requires that initial size of the cluster was defined during cluster bootstrap. It means that the cluster begins to work only when quorum number of nodes join the cluster.
Suppose there are 3 replicas and they want to run 3 ectd nodes. When the first replica starts an etcd node, it is not able to write and read from the etcd because 2 more etcd nodes need to join the cluster.
As an alternative, it is suggested that the first replica starts with etcd cluster which consists of only one etcd node. In this case it will be able to read and write to the etcd. When the second replica starts it can find the existing etcd cluster (using the address of the first replica) and just adds the second node to the cluster.
This allows us to have a working etcd cluster even when only some of the replicas are running.
Note: etcd has a Discovery Service Protocol. It is only used in the cluster bootstrap phase, and cannot be used for runtime reconfiguration.
The following algorithm describes the creating and updating of the etcd cluster during replica initialization based on an incremental approach.
Input
Each replica needs to have access to the following info which is provided during the replica starting:
- etcd cluster token value
- list of all replicas with corresponding values:
- replica id
- etcd node name
- etcd ip address
- ectd client and peer ports
Cluster Configuration Table
The table with the given columns will be maintained in etcd cluster:
- replica id
- timestamp
- running etcd server node flag
The last field indicates that a replica started an etcd server instance and that it had been alive at the time when the record to the Cluster Configuration Table was written.
Replicas to etcd nodes correspondence
Each replica can use a predefined function which returns the number of etcd nodes that are necessary to run for the given number of live replicas.
The function can be described in pseudocode like:
numberOfEtcdNodes(numberOfReplicas) {
1, 2 -> 1
3, 4 -> 3
5, ... -> 5
}Detecting added and failed replicas
It is suggested to use the heartbeat mechanism to detect failures in replicas. Each replica needs to repeatedly write a timestamp using the replica id as a key to the Cluster Configuration Table. When the difference between the current time and the timestamp of the replica is higher than a certain threshold, the replica is considered dead.
Detecting failed etcd nodes
etcd Admin API Documentation provides a REST api to check the health of an etcd node.
Initial state
The first initialized replica detects that there is no etcd cluster and starts an embedded etcd instance.
Main loop
Each replica reads the Cluster Configuration Table, checks the number of live replicas and calculates the number of required etcd nodes using the numberOfEtcdNodes(numberOfReplicas) function.
If the number of required etcd nodes is less than the current number of live etcd nodes, then only one replica with the lowest id that does not have a running embedded etcd node starts it and adds this node to the current cluster.
There can be two results:
- The embedded etcd is successfully run
- The replica which starts the etcd misses the timeout and is considered dead
If the etcd node initialization succeeds, the replica adds the record to the Cluster Configuration Table to let it know that it has running ectd node.
In both cases the process can be just repeated as is.